Postgres
Before I get into the contents of this post, I want to say that I am employed by https://neon.tech. If you want to use postgres without worrying about backups and memory usage, try out Neon Serverless Postgres.
Now that's out of the way, for my little web apps I run postgres on my VPS. However, I've always found a way to lose my data. My day job is managing connections to databases, and not managing the databases themselves, so this stuff I am a little rusty on.
I've always run the basic postgres docker image with no backups or replicas configured.
Since I have a new cluster now, I thought I should try something new. I recently read about
CloudNative PG on HN so I decided to look into it.
It got high praise from the replies, which is quite remarkable for HN.
It seems to have all the features I would want from a 'managed' postgres:
- Managed backups
- Easily create a new database
- Manage secrets
Backups
Since I always find a way to lose data, I should focus on backups.
CloudNativePG has a page on their backup configuration but I will elaborate on what I had to configure to get it working for me.
First, I decided to use S3 as my object store for backups the price seems good to me. To use S3, I need some credentials. I made a policy in IAM with the following permissions
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:ListBucket",
"s3:DeleteObject"
],
"Resource": [
"arn:aws:s3:::my-bucket",
"arn:aws:s3:::my-bucket/*"
]
}
]
}
I then created an IAM User with that policy only and created an access key. With that access key, I then configured the postgres cluster and the secrets:
kubectl -n postgres create secret generic backup-aws-creds \
--from-literal='ACCESS_KEY_ID=...' \
--from-literal='ACCESS_SECRET_KEY=...' \
--from-literal='AWS_REGION=...'
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: shared-cluster
namespace: postgres
spec:
instances: 2
# version of postgres to use
imageName: ghcr.io/cloudnative-pg/postgresql:15.3
# automated update of the primary once all
# replicas have been upgraded
primaryUpdateStrategy: unsupervised
# Require 4Gi of space
storage:
size: 4Gi
# prometheus metrics
monitoring:
enablePodMonitor: true
# backup config
backup:
barmanObjectStore:
destinationPath: "s3://my-bucket/postgres"
s3Credentials:
region:
name: backup-aws-creds
key: AWS_REGION
accessKeyId:
name: backup-aws-creds
key: ACCESS_KEY_ID
secretAccessKey:
name: backup-aws-creds
key: ACCESS_SECRET_KEY
wal:
compression: "bzip2"
encryption: "AES256"
data:
compression: "bzip2"
encryption: "AES256"
# Store 30days of backups
retentionPolicy: "30d"
# Backup from replicas preferred
target: "prefer-standby"
---
apiVersion: postgresql.cnpg.io/v1
kind: ScheduledBackup
metadata:
name: shared-cluster-backup-daily
namespace: postgres
spec:
# this runs daily at midnight
# cron : S M H D M W
schedule: "0 0 0 * * *"
backupOwnerReference: self
cluster:
name: shared-cluster
After applying this, my bucket in S3 starts receiving WAL objects.
Bootstrap
I already had an existing database I wanted to import, adding
spec:
bootstrap:
initdb:
import:
type: microservice
databases:
- dbname
source:
externalCluster: old-db
externalClusters:
- name: old-db
connectionParameters:
host: postgres
user: user
dbname: dbname
password:
name: dbcredentials
key: postgres_pass
worked flawlessly to import my data. Note, this is an 'offline' import so it's best to stop the service that is writing data into this DB
Recovery
A backup without tests is just wasted storage. Thankfully, CloudNativePG has good documentation on recovery practices.
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: shared-cluster-backup-test
namespace: postgres
spec:
instances: 1
# It is important that this image matches the
# image the original cluster uses.
imageName: ghcr.io/cloudnative-pg/postgresql:15.3
# Boostrap in recover mode
bootstrap:
recovery:
source: clusterBackup
externalClusters:
- name: clusterBackup
barmanObjectStore:
# name of the original cluster - can be omitted
# if the cluster names are the same
serverName: "shared-cluster"
destinationPath: "s3://my-bucket/postgres"
s3Credentials:
region:
name: backup-aws-creds
key: AWS_REGION
accessKeyId:
name: backup-aws-creds
key: ACCESS_KEY_ID
secretAccessKey:
name: backup-aws-creds
key: ACCESS_SECRET_KEY
wal:
compression: "bzip2"
encryption: "AES256"
data:
compression: "bzip2"
encryption: "AES256"
Resource limits
Databases can be pretty heavy. After running my database for a little while, I monitored the resource usage in OpenLens to get a feel for what I wanted the resource limits to be.
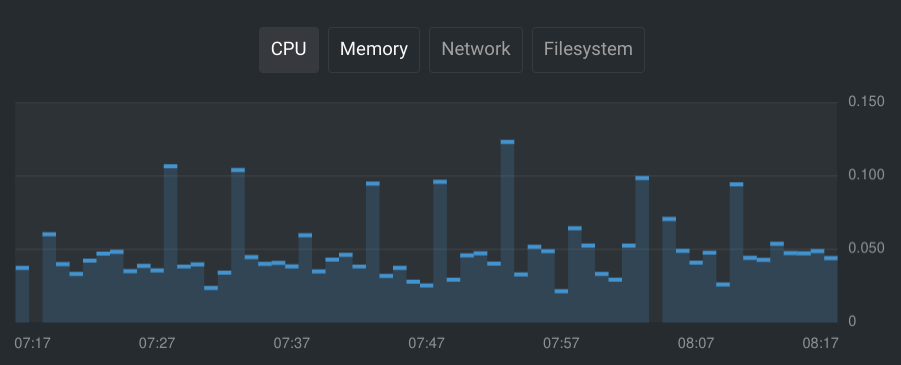
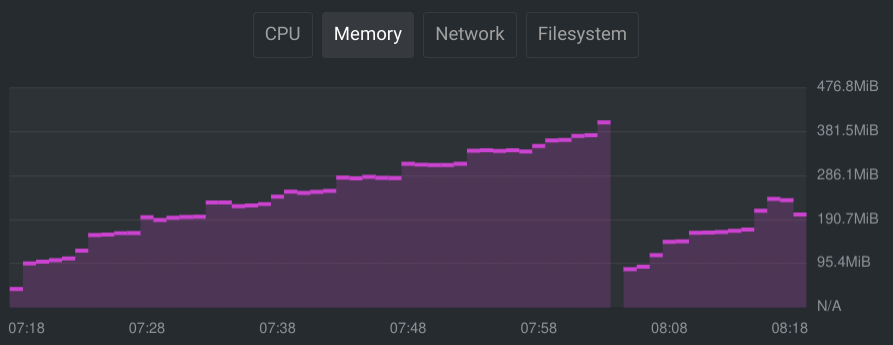
Based on the graphs, I decided to go with
spec:
postgresql:
parameters:
# should be 25% the memory limit
shared_buffers: "128MB"
resources:
requests:
memory: "512Mi"
cpu: "50m"
limits:
memory: "512Mi"
cpu: "150m"
Updating Postgres
I started my cluster on postgres 15, but I am comfortable running postgres 16 now. Before I update the cluster, I will create a backup
apiVersion: postgresql.cnpg.io/v1
kind: Backup
metadata:
name: shared-cluster-backup
namespace: postgres
spec:
cluster:
name: shared-cluster
After the backup is completed, all I need to do is update the imageName field in the Cluster spec.
The unsupervised update strategy will take over and update all the instances automatically.
Unfortunately, this doesn't work today. See the discussion
The Cluster "shared-cluster" is invalid: spec.imageName: Invalid value: "ghcr.io/cloudnative-pg/postgresql:16.0": can't upgrade between ghcr.io/cloudnative-pg/postgresql:15.3 and ghcr.io/cloudnative-pg/postgresql:16.0To perform the migration, it's necessary to create a new cluster and use the initdb to pgrestore the database.
Complaints
There's a feature I'd really like, and I tried to implement it, but I've given up for now. CloudNativePG has made the decision that there should only be one database per cluster. I would have preferred a construction where you run one cluster but can create many databases in different namespaces.
The idea is that you would create your cluster definition, this will handle the initdb settings,
the backup settings, the replication settings, superuser etc. On top f that, there is a database CRD that
will create the new application user and database that was requested.
It's true that having more clusters would scale better, but I'm not looking to scale. I'm looking to reduce my memory and CPU usage.